In this post, I introduce a web interface that I have been working on as part of my PhD. It summarizes the extended abstract “Web Interface for Exploration of Latent and Tag Spaces in Music Auto-Tagging” that had been accepted to Machine Learning for Media Discovery Workshop, ML4MD as part of International Conference on Machine Learning, ICML 2020. The interface will be much more of an interest to the MIR researchers, but it can be also be used by regular users to explore music. You can check out the poster here. Here is the link to the interface: music-explore.upf.edu.
Simplest use-case: tag exploration
The core concept of this interface is that you can see multiple segments (from 1 to 3 sec) of music tracks visualized as dots. The simplest use case is to select two tags that can represent genres, moods, instruments, or other aspects of music (e.g. rock, guitar, calm, Indian, 80s) and explore the segments according to selected tags. The positive direction of axes means that the computer thinks that music can indeed be characterized in that way. And when you mouse over the dots on the graph, you will hear that audio segment. Here are the steps to explore tags:
- You can increase the number of tracks that will be displayed on the graph, but beware that too many might be heavy on your device (start with 100).
- Make sure that taggrams is selected, not embeddings.
- Select the tags that you are interested in exploring.
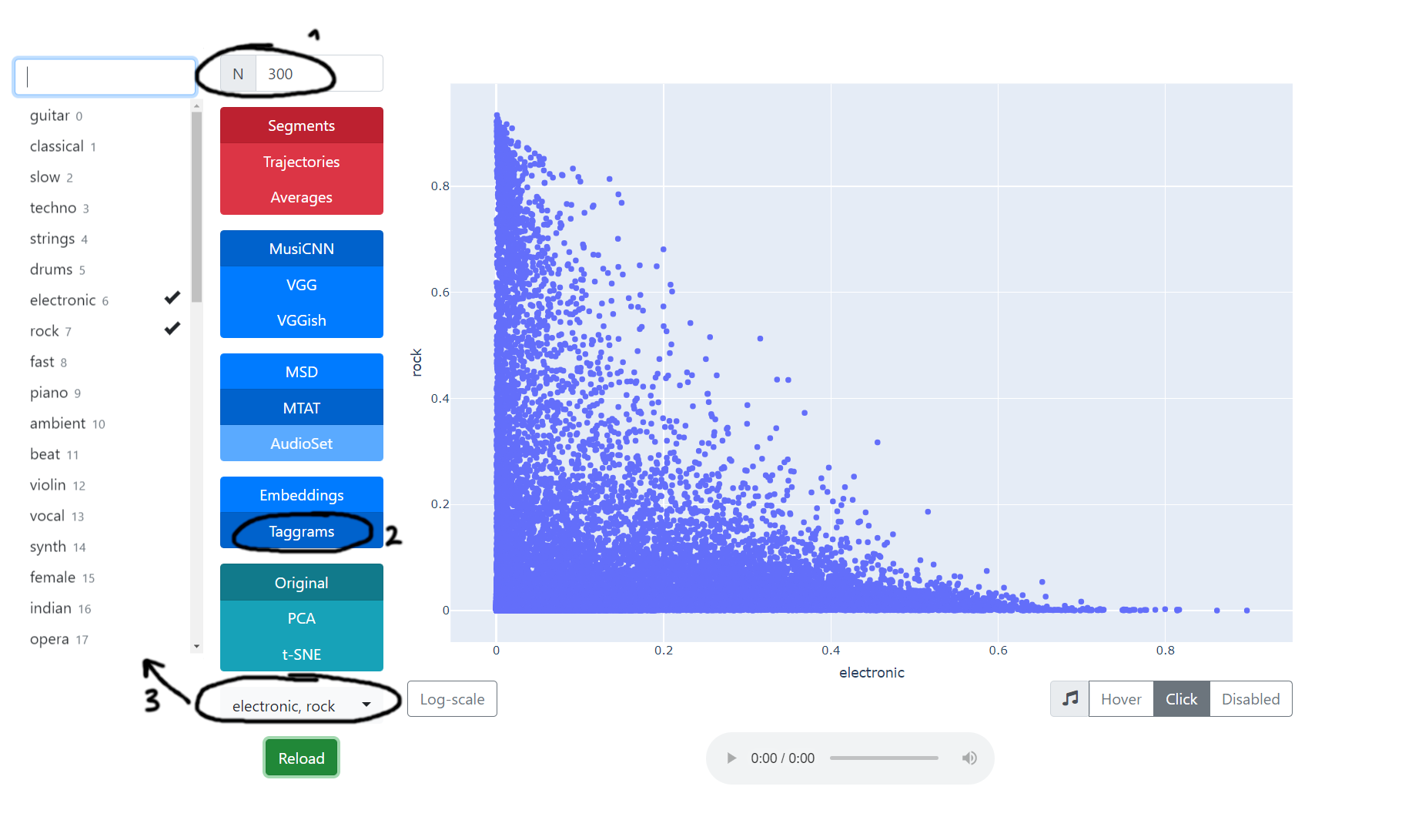
So in the example on the image, the segments in the top should be rock-ish, the segments on the right should be electronic, and the center should have rock with electronic elements! If you want to try a slightly different set of tags, you can change MTAT to MSD.
Explanation of interface
There are several modes of visualizing tracks:
- Segments – each track segment (1 to 3 sec) is visualized as a point on the graph
- Trajectories – each track is visualized as a line that connects its consecutive segments
- Averages – each track is represented as a circle that is an average of its segments with the diameter proportional to the standard deviation
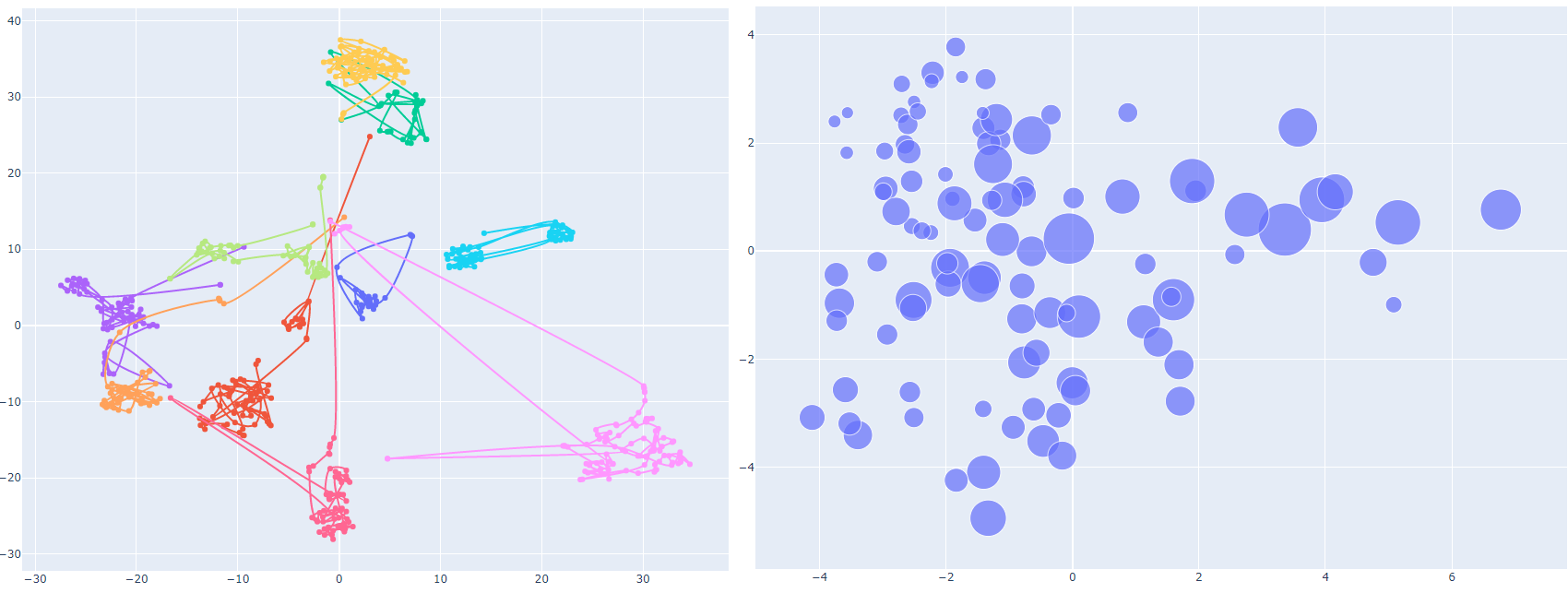
Some technical details
The purpose of this interface is both exploration of latent spaces and evaluation of auto-tagging models. These are deep learning models, which take audio as input and output the activation value for each tag.
We took MTG-Jamendo dataset, as its audio is available under Creative Commons licenses, used pre-trained deep learning models from Essentia TensorFlow:
- MusiCNN pre-trained on top 50 tags from MagnaTagATune (MTAT) and Million Song Dataset (MSD)
- VGG (implementation by Jordi Pons) also pre-trained on top 50 tags in MTAT and MSD
- VGGish pre-trained on AudioSet
More details about the models and datasets are provided in the extended abstract.
All 4 models: MusiCNN and VGG pre-trained on MTAT and MSD provide taggrams where we have the activation values for tags and embeddings which are the activation values of the neurons in the hidden layer. Embeddings’ size is quite bigger than the number of tags (50), so they potentially capture more of the essence of the music before it is condensed into the tags. VGGish model only provides embeddings. The size of embeddings are MusiCNN – 200, VGG – 256, VGGish – 128.
Dimensions
Obviously, as we have quite a high-dimensional spaces to visualize in 2D, we provide several options to do the projection:
- Original – select 2 out of many of the original dimensions. Those are tags for taggrams and unnamed dimensions for the embeddings
- PCA – select several of first principal components (PC) to capture the most variance in the space. It is quite interesting to explore the segments in the PCA projection as there are some interesting behaviors as you move around the perimeter
- t-SNE (warning – slow!) – use t-SNE transformation to maximize the separation of the segments. As it is quite slow and resource intense, only use it for a small number of tracks (10 - 50). However, it works quite well with the trajectories, where you can see clusters of segments that represent different sections or the track
Future work
We plan to conduct several user experiments to see how subjective is the semantics of the PCA dimensions. If you are interested in participating, please send me an email or tweet at me.
The next step in my PhD is to create a prompt-based system that would guide you in the latent space to explore and find new music based on the user’s current goals and moods possibly utilizing reinforcement learning.
Check out the extended abstract if you want more details, send me an email or tweet at me if you are interested in collaborations or have some useful feedback!